Map Reduce
- Crucial element of Hadoop
- Enhances its power and efficiency
- Operates as a programming model for processing large datasets efficiently in parallel, distributed fashion. Initially, data is divided and later combined to generate the final result. MapReduce libraries are implemented in multiple programming languages, each with various optimizations. In Hadoop, the objective is to map jobs and then reduce them to equivalent tasks, minimizing network overhead and processing power. The MapReduce task comprises two main phases: Map Phase and Reduce Phase.
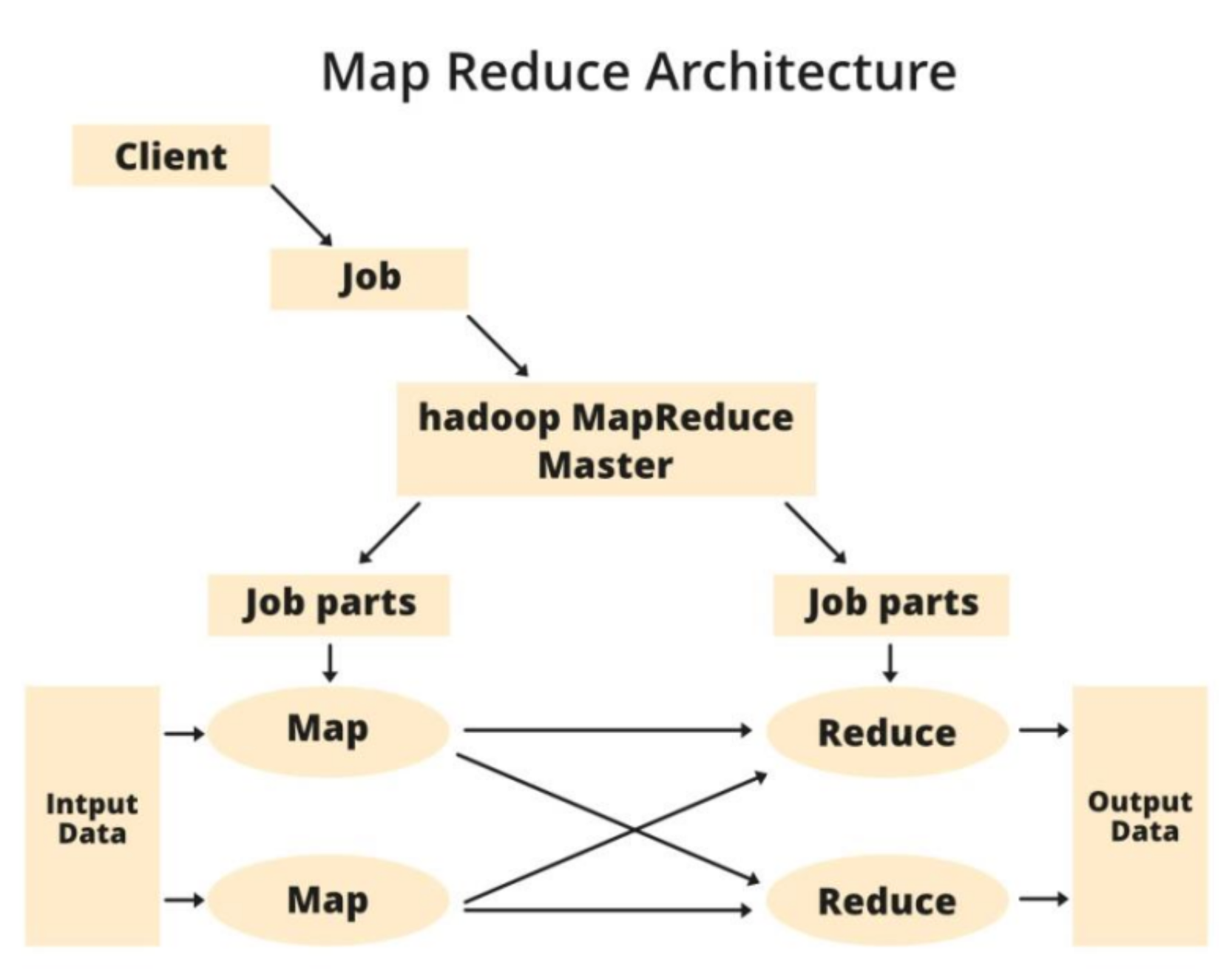
Components of MapReduce Architecture
-
Client:
- Definition: Initiates job processing by submitting tasks to the Hadoop MapReduce Manager.
- Characteristics: Multiple clients can continuously send jobs for processing.
-
Job:
- Definition: A MapReduce job represents the actual work the client wants to perform, consisting of numerous smaller tasks for processing or execution.
-
Hadoop MapReduce Master:
- Role: Divides a specific job into smaller job-parts for efficient processing.
-
Job-Parts:
- Definition: Sub-jobs or tasks derived from dividing the main job, with their results combined to produce the final output.
-
Input Data:
- Description: The dataset provided to MapReduce for processing.
-
Output Data:
- Description: The conclusive result obtained after the processing of MapReduce tasks.
In MapReduce, the process begins with a client submitting a job to the Hadoop MapReduce Master. The master divides the job into equivalent parts, which are then assigned to Map and Reduce tasks. These tasks contain programs tailored to the specific use-case requirements of the company. Developers write logic to meet industry needs. The input data is processed by the Map Task, generating intermediate key-value pairs. The Map output is then passed to the Reducer, which produces the final output stored in HDFS. Multiple Map and Reduce tasks can be employed based on the data processing requirements. The Map and Reduce algorithm is optimized to minimize time and space complexity.
The MapReduce task is primarily divided into two phases: the Map phase and the Reduce phase.
-
Map:
- Function: Maps input data into key-value pairs.
- Input: Key-value pairs, where the key can represent an address ID and the value is the associated data.
- Execution: The Map() function processes each input key-value pair in its memory repository, generating intermediate key-value pairs for the Reducer.
-
Reduce:
- Function: Aggregates or groups intermediate key-value pairs, which have been shuffled, sorted, and sent to the Reduce() function.
- Process: The Reduce() function applies the developer-written algorithm to aggregate or group data based on key-value pairs.
-
Job Tracker:
- Responsibility: Manages resources and jobs across the cluster.
- Scheduling: Schedules each map on the Task Tracker, usually on the same data node.
- Cluster Management: Oversees the entire cluster, coordinating tasks across potentially hundreds of data nodes.
-
Task Tracker:
- Role: Acts as the working unit, executing instructions from the Job Tracker.
- Deployment: Deployed on each node in the cluster.
- Tasks: Executes both Map and Reduce tasks as directed by the Job Tracker.